
ご無沙汰しております。ProfessionalService事業部の小松です。
Postgresqlを利用していると、テーブルとIndexがだんだんと肥大化し、パフォーマンス問題に繋がることがあります。こんな時にはpg_repackを使うというドキュメントが公開されていました。
このドキュメントにはEC2やDB接続可能なコンピュータから実行する旨の記載がありましたが、このためだけにEC2を利用するのもイマイチなので、コンテナ化してFargateで実行してみました。
コンテナイメージの作成
まずはDockerイメージを作成します。
ベースイメージはubuntuを利用することとし、対象のAuroraエンジンバージョンは16.4を想定します。
AWSが公開している以下のページから、該当するpg_repackのバージョンが1.5.0であることを確認し、今回は1.5.0をインストールします。
※pg_repackの最新バージョンは1.5.2となっていますが、1.5.0を指定しないと動きません。バージョン互換が泣きたいくらい無いので、利用しているエンジンバージョンに合わせてpg_repackのバージョンを指定する必要があります。
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraPostgreSQLReleaseNotes/AuroraPostgreSQL.Extensions.html
今回作成したDockerfileはこちら
FROM ubuntu:24.04
RUN apt-get update \
&& apt-get upgrade -y \
&& apt-get install --no-install-recommends -y \
build-essential \
liblz4-dev \
libreadline-dev \
libzstd-dev \
postgresql-server-dev-16 \
python3-dev \
python3-pip \
python3-venv \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN python3 -m venv /opt/venv \
&& /opt/venv/bin/pip install --no-cache-dir --upgrade \
pip \
pgxnclient
ENV PATH=/opt/venv/bin:/usr/lib/postgresql/16/bin:${PATH}
RUN pgxn install pg_repack=1.5.0
RUN useradd -s /bin/bash -m pguser
USER pguser
ENV USER=pguser
ENTRYPOINT ["/usr/lib/postgresql/16/bin/pg_repack", "-k"]pg_repackのバージョンが1.4.8や、それ以下になる場合は、インストールするパッケージが変わってきますのでご注意ください。
ECSタスク定義の作成
次に、ECSタスク定義を作成します。
対象とするAurora のエンドポイントはパラメータストア、ユーザとパスワードはSecretManagerに格納されているものを環境変数に取り込むことで、pg_repackの実行時に指定が可能になります。
{
"taskDefinitionArn": "arn:aws:ecs:ap-northeast-1:[accountID]:task-definition/pg_repack:",
"containerDefinitions": [
{
"name": "pg_repack",
"image": "[accountID].dkr.ecr.ap-northeast-1.amazonaws.com/pg_repack:latest",
"cpu": 0,
"portMappings": [],
"essential": true,
"environment": [],
"mountPoints": [],
"volumesFrom": [],
"secrets": [
{
"name": "PGHOST",
"valueFrom": "arn:aws:ssm:ap-northeast-1:[accountID]:parameter/komatsu/pg-repack-test/db-host"
},
{
"name": "PGPASSWORD",
"valueFrom": "arn:aws:secretsmanager:ap-northeast-1:[accountID]:secret:rds!cluster-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx-xxxxxx:password::"
},
{
"name": "PGUSER",
"valueFrom": "arn:aws:secretsmanager:ap-northeast-1:[accountID]:secret:rds!cluster-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx-xxxxxx:username::"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/pg_repack",
"mode": "non-blocking",
"awslogs-create-group": "true",
"max-buffer-size": "25m",
"awslogs-region": "ap-northeast-1",
"awslogs-stream-prefix": "ecs"
},
"secretOptions": []
},
"systemControls": []
}
],
"family": "pg_repack",
"executionRoleArn": "arn:aws:iam::[accountID]:role/ecsTaskExecutionRole",
"networkMode": "awsvpc",
"revision": 1,
"volumes": [],
"status": "ACTIVE",
"requiresAttributes": [
{
"name": "com.amazonaws.ecs.capability.logging-driver.awslogs"
},
{
"name": "ecs.capability.execution-role-awslogs"
},
{
"name": "com.amazonaws.ecs.capability.ecr-auth"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.19"
},
{
"name": "ecs.capability.secrets.asm.environment-variables"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.28"
},
{
"name": "ecs.capability.execution-role-ecr-pull"
},
{
"name": "ecs.capability.secrets.ssm.environment-variables"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.18"
},
{
"name": "ecs.capability.task-eni"
},
{
"name": "com.amazonaws.ecs.capability.docker-remote-api.1.29"
}
],
"placementConstraints": [],
"compatibilities": [
"EC2",
"FARGATE"
],
"requiresCompatibilities": [
"FARGATE"
],
"cpu": "512",
"memory": "1024",
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
},
"registeredAt": "2025-02-26T11:21:41.610Z",
"registeredBy": "arn:aws:iam::[accountID]:[username]",
"enableFaultInjection": false,
"tags": []
}なお、pg_repackで利用できる環境変数は以下に記載がありますが、テーブルを指定するための環境変数はありません。データベース全体へ実行することになりますので、テーブル指定で行う場合は、Dockerfile内でオプション指定する必要があります。
https://www.postgresql.org/docs/current/libpq-envars.html
実行してみる
では、ちゃんとpg_repackが機能しているかどうか確認していきます。
psqlクライアントから該当のAuroraに接続して、テスト用のデータを用意します。
$ psql -h pg-repack-test.cluster-xxxxxxxx.ap-northeast-1.rds.amazonaws.com -U postgres
#テーブル作成
postgres=>
CREATE TABLE test_table (
id integer PRIMARY KEY,
first_name varchar(128),
last_name varchar(128),
number integer,
update_dt timestamp
);
#テストデータ作成
postgres=>
INSERT INTO test_table (id, first_name, last_name, number, update_dt)
SELECT i, format('太郎%s', i),
format('山田%s', i), 100, now()
FROM generate_series(1,200000) as i;
#データ更新
postgres=>
UPDATE test_table SET number = 200, update_dt = now();
#データ削除
postgres=>
DELETE FROM test_table WHERE (id BETWEEN 1 AND 100000);
postgres=>
SELECT pg_size_pretty(pg_table_size('test_table')) as table_size,
pg_size_pretty(pg_indexes_size('test_table')) AS index_size,
pg_size_pretty(pg_total_relation_size('test_table')) AS total;
table_size | index_size | total
------------+------------+-------
28 MB | 8792 kB | 36 MB内容としてはID、姓、名、数字、更新日を持つテーブルに 20万件のテストデータを作成、その後全件の数字を更新した後、10万件のデータを削除したテーブルとなります。
これは、10万件のデータを削除したにもかかわらずテーブルのデータ量は変わっておらず、これがデータベースの肥大化に原因になります。これをpg_repackにより整理することになります。
先ほど作成したタスク定義を指定して適当なクラスターでRunTaskを実行していきます。
※RDSへ接続可能なサブネットおよびセキュリティグループを指定します。
aws ecs run-task \
--cluster komatsu-test-cluster \
--task-definition arn:aws:ecs:ap-northeast-1:xxxxxxxxxxx:task-definition/pg_repack \
--launch-type FARGATE \
--network-configuration "awsvpcConfiguration={subnets=["subnet-xxxxxxxx","subnet-xxxxxxxx"], securityGroups=[sg-xxxxxxxx], assignPublicIp=ENABLED}"今回は小さいテーブルなのでそこまで時間がかからずに1~2分もあればタスクが終了するかと思います。
タスクが終了した後に再度テーブルサイズを確認してみます。
postgres=> SELECT pg_size_pretty(pg_table_size('test_table')) as table_size,
pg_size_pretty(pg_indexes_size('test_table')) AS index_size,
pg_size_pretty(pg_total_relation_size('test_table')) AS total;
table_size | index_size | total
------------+------------+---------
7504 kB | 2208 kB | 9712 kBざっと4分の1くらいまで肥大化したテーブルを解消することができました。
更新・削除が頻繁に行われるデータベースについては定期的にこれを実行するのが好ましいことがわかります。
RunTaskにてpg_repackを実行することができました。これをスケジュールされたタスクに登録すると指定間隔やcronで指定したタイミングで実行することができるので、運用の自動化をすることもできるかと思います。
Advanced
RunTaskで自動化もよいのですが、StepFunctions を利用してもう少し高度な自動実行環境を作ってみました。
今回はpg_repackの実行前と実行後にテーブルサイズを確認して、最後にSNSにて実行前後のサイズをメール送信するようなステートマシンを作成してみます。
※今回はエラーハンドリングを省略
Lambda関数の作成
テーブルサイズを確認するSQLをAuroraに対して発行する Lambda関数を作成します。
今回は psycopg2 を利用するため、事前にLambdaレイヤーを登録しておきます。
$ mkdir lambda
$ cd lambda/
$ echo 'psycopg2-binary' > requirements.txt
$ docker run -v "$PWD":/var/task "public.ecr.aws/sam/build-python3.13:latest" /bin/sh -c "pip install --platform manylinux2014_x86_64 --target . --python-version 3.13 --only-binary=:all: -r requirements.txt -t python/; exit"
$ zip -r layer.zip python
$ aws lambda publish-layer-version --layer-name psycopg2-binary-3-13 --zip-file fileb://layer.zip --compatible-runtimes python3.13次に、テーブルサイズを確認するLambdaFunctionを用意します。今回は、pg_repackの実行前後で同じFunctionを利用できるように、パラメータをresponseのMessageに含めることができるようにすることで、汎用的にしてみました。
※DBに接続するための情報は環境変数から取得する形にするため、Lambdaの設定にて環境変数の設定を行う必要があります。
import json
import os
import psycopg2
from psycopg2.extras import RealDictCursor
def lambda_handler(event, context):
try:
# 環境変数からデータベース接続情報を取得
db_host = os.environ['DB_HOST']
db_name = os.environ['DB_NAME']
db_user = os.environ['DB_USER']
db_password = os.environ['DB_PASSWORD']
db_port = os.environ.get('DB_PORT', 5432)
option = event.get('option', "")
# イベントからSQLクエリとパラメータを取得
sql_query = 'SELECT pg_size_pretty(pg_table_size(\'test_table\')) as table_size,'\
'pg_size_pretty(pg_indexes_size(\'test_table\')) AS index_size,'\
'pg_size_pretty(pg_total_relation_size(\'test_table\')) AS total;'
# データベースに接続
conn = psycopg2.connect(
host=db_host,
database=db_name,
user=db_user,
password=db_password,
port=db_port
)
# RealDictCursorを使用して結果を辞書形式で取得
with conn.cursor(cursor_factory=RealDictCursor) as cur:
# SQLクエリを実行
cur.execute(sql_query)
result = cur.fetchall()
response = {
'statusCode': 200,
'body': {
'message': '%s Table Size:' % option,
'result': result,
}
}
# 接続を閉じる
conn.close()
return response
except psycopg2.Error as e:
# PostgreSQLエラーの処理
return {
'statusCode': 500,
'body': json.dumps({
'error': 'データベースエラー',
'details': str(e)
})
}
except Exception as e:
# その他のエラーの処理
return {
'statusCode': 500,
'body': json.dumps({
'error': '内部サーバーエラー',
'details': str(e)
})
}実行結果は以下のようになります。
Input
{
"option": "afater"
}
Response
{
"statusCode": 200,
"body": {
"message": "afater Table Size:",
"result": [
{
"table_size": "7504 kB",
"index_size": "2208 kB",
"total": "9712 kB"
}
]
}
}StateMachineの作成
以下のようなステートマシンを作成していきます。
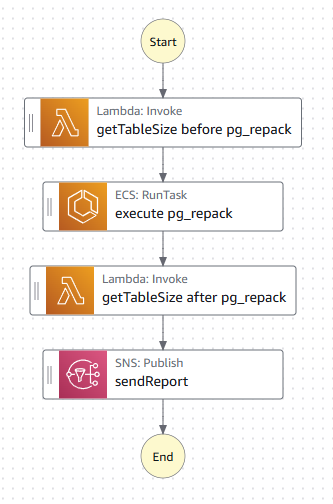
今回は、昨年11月に発表されたStepFunctionsのVariables、JSONataを利用してみます。
Lambdaで実行して取得したテーブルサイズを変数に格納し、最後のSNSのMessage本文で変数の値をPublishするようにしました。
{
"StartAt": "getTableSize before pg_repack",
"States": {
"getTableSize before pg_repack": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Output": "{% $states.result.Payload %}",
"Arguments": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:[accountID]:function:scan_postgresql_table_size:$LATEST",
"Payload": {
"option": "before"
}
},
"Assign": {
"beforeTableSize": "{% $states.result.Payload.body %}"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2,
"JitterStrategy": "FULL"
}
],
"Next": "execute pg_repack"
},
"execute pg_repack": {
"Type": "Task",
"Resource": "arn:aws:states:::ecs:runTask.sync",
"Arguments": {
"LaunchType": "FARGATE",
"Cluster": "arn:aws:ecs:ap-northeast-1:[accountID]:cluster/komatsu-test-cluster",
"TaskDefinition": "arn:aws:ecs:ap-northeast-1:[accountID]:task-definition/pg_repack",
"NetworkConfiguration": {
"AwsvpcConfiguration": {
"AssignPublicIp": "DISABLED",
"SecurityGroups": [
"sg-xxxxxxxx"
],
"Subnets": [
"subnet-xxxxxxxx",
"subnet-xxxxxxxx"
]
}
}
},
"Next": "getTableSize after pg_repack"
},
"getTableSize after pg_repack": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Output": "{% $states.result.Payload %}",
"Arguments": {
"FunctionName": "arn:aws:lambda:ap-northeast-1:[accountID]:function:scan_postgresql_table_size:$LATEST",
"Payload": {
"option": "after"
}
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2,
"JitterStrategy": "FULL"
}
],
"Assign": {
"afterTableSize": "{% $states.result.Payload.body %}"
},
"Next": "sendReport"
},
"sendReport": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Arguments": {
"TopicArn": "arn:aws:sns:ap-northeast-1:[accountID]:Topic",
"Message": "{% $beforeTableSize & $afterTableSize %}"
},
"End": true
}
},
"QueryLanguage": "JSONata"
}SNS Topicに自分のメールアドレスをSubscribeしておくと、以下のようなメールが通知されます。
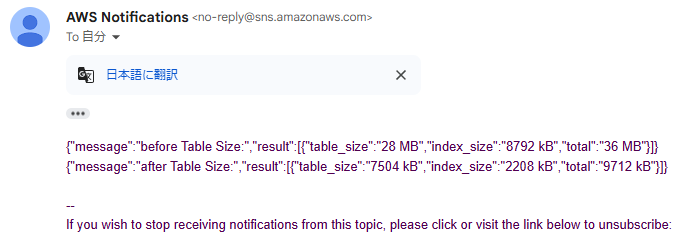
このState machineをAmazon EventBridge Schedulerから実行するようにすれば、どれくらいpg_repackで肥大化を解消できたかをメールでレポートされるところまで実装ができるようになります。
まとめ
今回はpg_repackの実行環境構築を自動化まで見据えて構築しました。
更新が頻繁に行われるデータベースでは、肥大化はパフォーマンスだけではなくコストにも影響してくるため、VACUUMやpg_repackの実行はとても重要になってきます。
pg_repackはVACUUMコマンドとは異なり、実行中に対象テーブルを排他ロックを保持し続けないため、オンライン中に動作させる事が可能です。
是非参考にしていただければと思います。
