
こんにちは。アイディーエスの岡田です。
re:Invent2024にて発表されたS3 Tablesについて、実際に触りつつお伝えします。
新機能に触れてみたい方の参考となれば幸いです。
はじめに
S3 Table とは、分析ワークロードに最適化されたストレージを提供するサービスです。
汎用バケットにオブジェクトを格納するように、テーブルバケットにはテーブルを格納します。
テーブルの形式は、Apache Iceberg 形式をサポートしています。
テーブルバケットを作成してみる
早速、実際にテーブルバケットを作成し、データの格納と参照をしてみます。
公式ドキュメントのチュートリアルを参考に、設定時に気を付けるべき点を記載します。
なお、手順は全てバージニア北部(us-east-1)リージョンで実施しています。
①テーブルバケットを作成する
もし「AWS 分析サービスとの統合 – プレビュー」が有効になっていない場合は、併せて有効にしましょう。
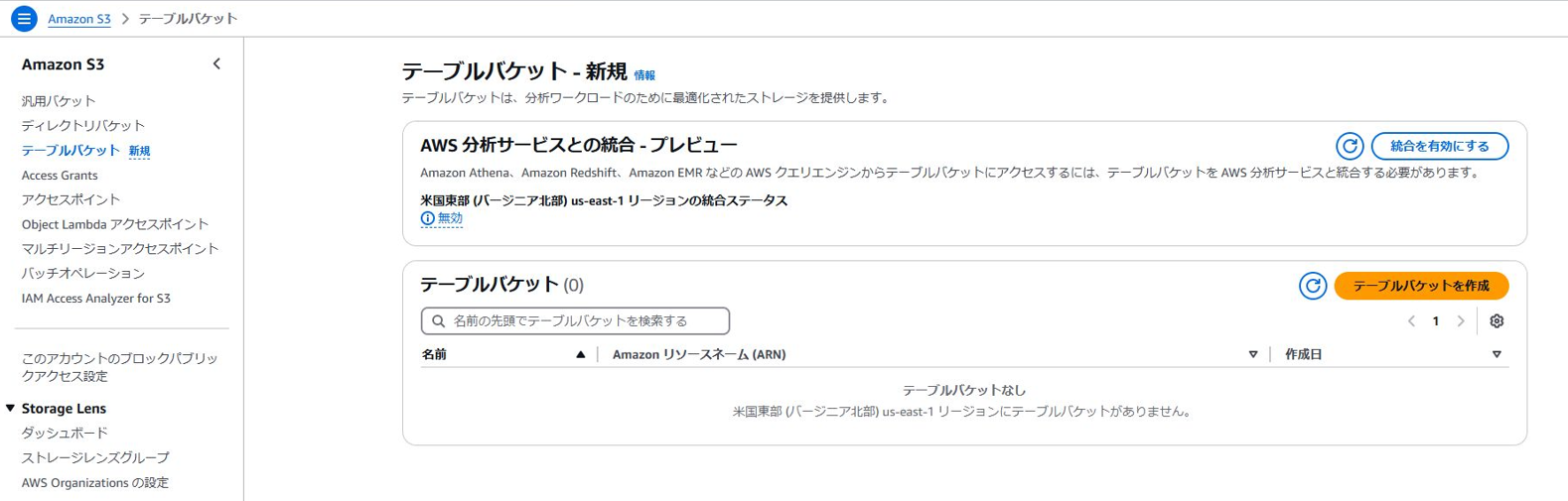
今回は以下のようにテーブルバケットを作成しました。
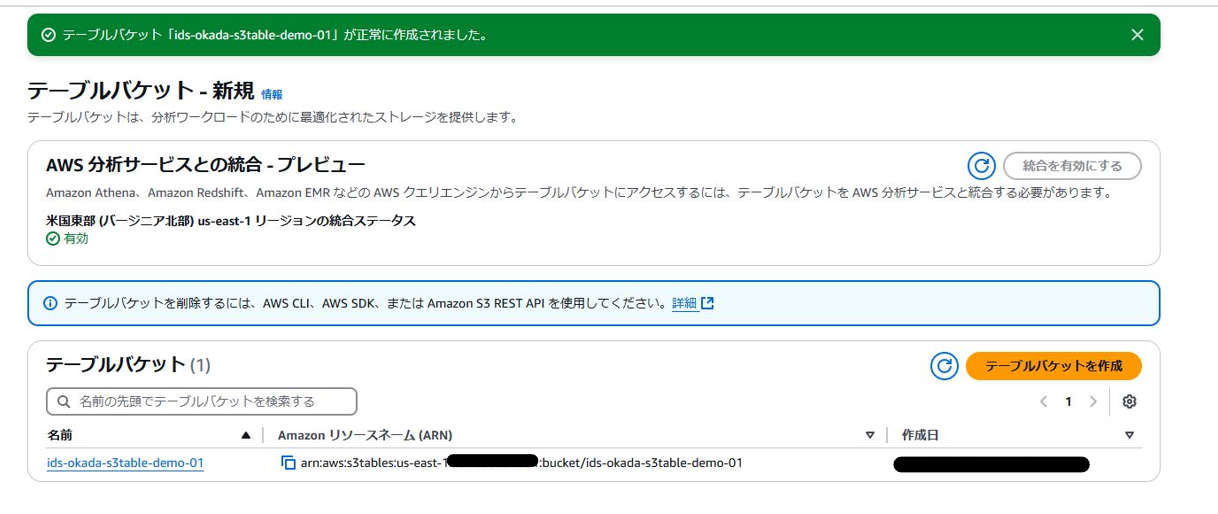
② EMR クラスターの作成
汎用バケットと異なり、テーブルバケットのコンソール画面から直接データを格納することはできません。
今回はEMRクラスター上でSparkを起動し、そこからデータを格納します。
Amazon EMR > クラスターから「クラスターを作成」を押し、クラスター作成画面に入ります。
基本的にデフォルトの設定で問題ありませんが、一部変更します。
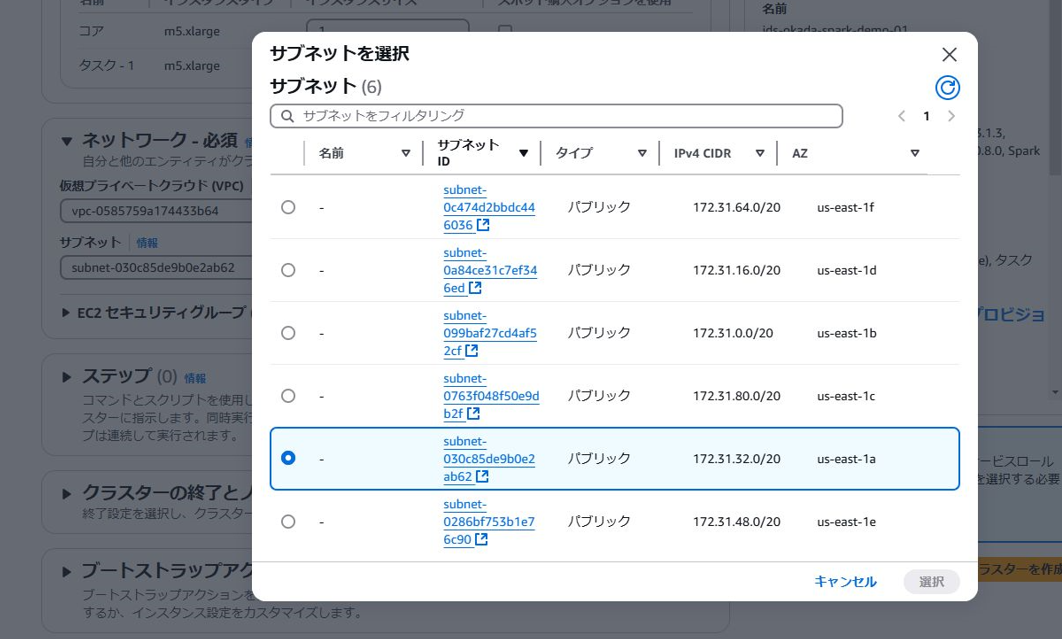
・ネットワーク設定
→us-east-1a上のサブネットを選択します。
私の環境ではデフォルトでus-east-1eのサブネットが選択されていたのですが、このAZではインスタンスタイプが利用できず、EC2起動に失敗します。
・ソフトウェア設定
チュートリアル通り、下記を設定します。
[{
"Classification":"iceberg-defaults",
"Properties":{"iceberg.enabled":"true"}
}]・セキュリティ設定と EC2キーペア
ここでキーペアを作成し、それを設定しましょう。
後でEC2へSSH接続する際に必要となります。
・Amazon EMR サービスロール
「サービスロールを作成」を選択します。
・Amazon EMR の EC2 インスタンスプロファイル
「インスタンスプロファイルを作成」を選択し、「読み取りおよび書き込みのアクセス権を持つ、このアカウントのすべての S3 バケット」を選択します。
この手順ではテーブルバケットへの権限は付与されませんが、一旦進めます。
ここまで設定できたら、「クラスターを作成」をクリックします。
数分待つと起動し、EC2 インスタンスのステータスが「実行中」になります。
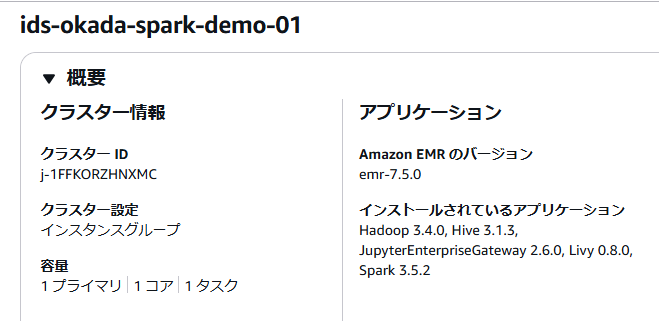
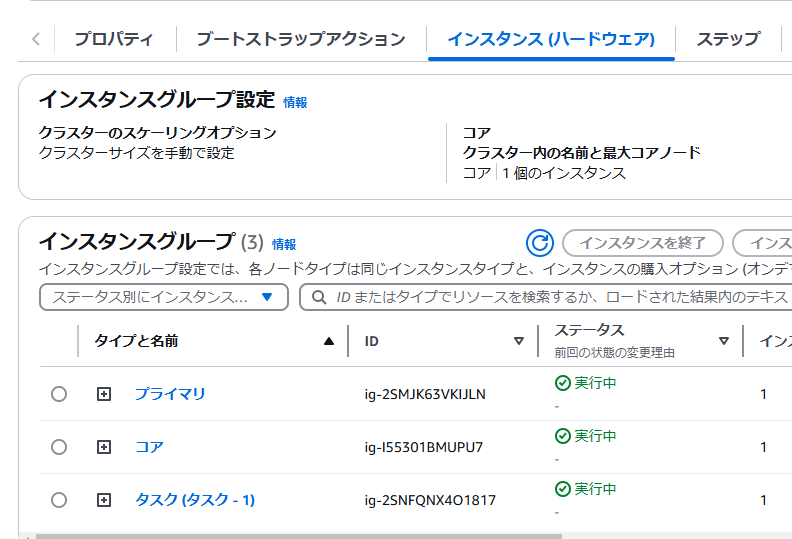
その後プライマリインスタンスに対し、追加で以下の設定を行います。
・ IAM ロールに「AmazonS3TablesFullAccess」ポリシーをアタッチする
・セキュリティグループへ、自身の端末からSSH接続(ポート20)を許可するインバウンドルールを追加する
③データを格納/参照する
この後はチュートリアルに従ってSpark セッションを起動し、データを格納したり参照してみましょう。
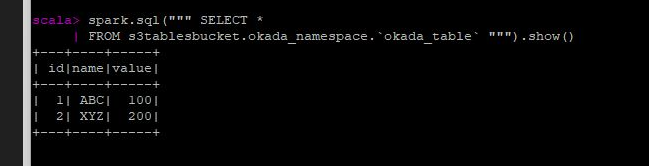
最終的には画像のように格納したデータを取得できました。
さいごに
今回はS3 Tablesを実際に触ってみました。
是非みなさんもお試しいただければ幸いです。
