
こんばんは。小寺です。
今日は、Anthropic Claudeをテーマにしたアドベントカレンダーに参加させていただいております。
本記事は2023年12月16日時点での情報を元に記載しています。ご紹介させていただいているBuilding with Amazon Bedrock and LangChain Workshopの内容は、随時更新されているようです。
LangChainとは?
LangChainについて簡単にまとめてみました。
・Large Language Model(以下、LLM)を使ったアプリケーション開発のフレームワークライブラリ
・モデル/メモリ/エージェント/Retirieverなどの機能が抽象化されているので、少ないコードで効率的な開発やアウトプットができる
LLMアプリを作るには、単純な応答だけではなく複数のワークフロー処理を行う必要があります。
LLM上でナレッジがない場合の専門知識の回答や、意図した形式での回答をしてほしい場合にこそLangChainの出番かと思います。
LangChainはPythonやJavaScript、TypeScriptなどのプログラミング言語で利用できます。Python版ではLangChainに含まれている全ての機能が利用できるため、Pythonでの利用がおすすめです。
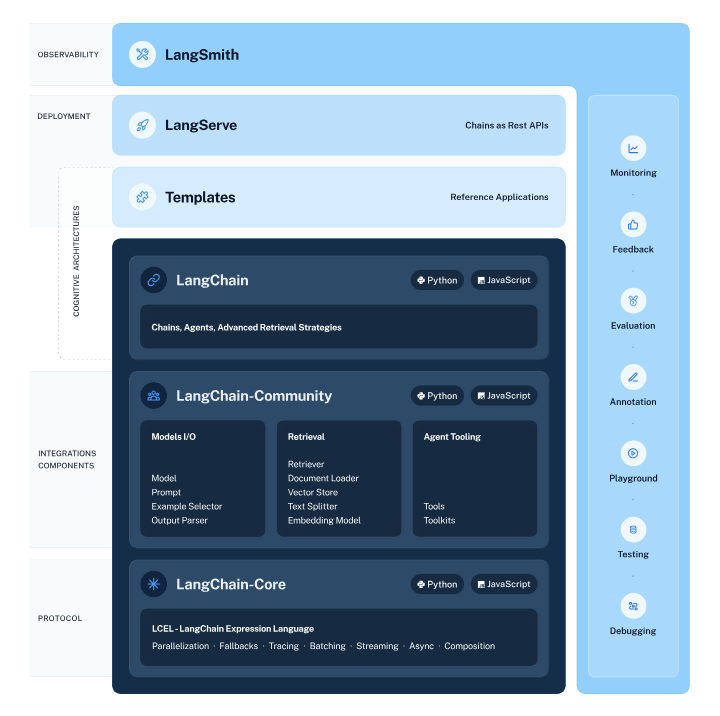
LangChainのモジュール
Models:異なるモデルを組み合わせ
Modelsは、様々なモデルを組み合わせて使用できる機能です。
LangChainではLLMやチャットモデル、テキスト埋め込みモデルなど様々なモデルを利用することが可能です。
LangChainに組み込まれたモデルを使うと、コーディングなどの手間が省けます。
Prompts
Promptsはプロンプトの入力にあたります。LangChainにはプロンプトの管理や最適化、シリアル化などの機能がパッケージ化されているため、コーディングの不可軽減ができます。
また、複数名のチームで開発する際に、記述方法の統一化ができます。
Indexes
インデックスは既存のドキュメントとLLM を組合わせて使うのに役立つ機能です。PDFやExcel、CSVなど外部のデータをもとに回答を生成できるようになります。
通常は文章によるプロンプトの入力が必要です。LangChainを用いて機能を拡張すると、外部データを使用してより効率的に指示を送ることができます。
Chains
Chainsとは、複数のプロンプトが実行でき、一連の動作をスムーズに行えます。
通常の言語モデルでは、ユーザーが入力したプロンプトに対してAIによる回答が出力されるます。
Chainsの機能を活用することで文字数の多いテキストを要約する際に、まず元の文章をいくつかのパートに分けて要約することができ、各パートの要約を入力として、全体の要約を出力できます。
複数のプロンプトを実行すると、より正確な回答を得られる場合があります。
Retrieval
PDFやCSVなどの外部データを用いて回答を生成する機能で、LLMがまだ学習していない、もしくは学習できなかった外部データを含めて回答します。
Agents
プロンプトと合わせて、ツールを利用してアクションし、その結果を回答に組み合わせることができます。
情報収集を行うための検索エンジンと、グラフを作成するためのPythonコードなどを組み合わせて活用できます。
最新情報も追加して、回答してもらいたいときにプロンプトと共にGoogle検索やBing検索のツールを利用して情報を取りにいき、回答に含めることができます。
Memory
Memoryとは、状態(state)を保存する機能です。そのMemoryに保存されたデータを必要に応じて再度活用することもできます。Memoryには、短期記憶と長期記憶と呼ばれる2種類の形式があります。
短期記憶は、一つのやりとりの中でデータを保持する機能です。入力した文章を要約する処理などで短期記憶が使用されます。
長期記憶は、複数のやりとりでデータを保持する機能です。ユーザーとの対話中に得た情報をもとに記憶を更新し、その後のやりとりに反映できます。
LangChainでClaudeを使ってみるために、ハンズオン「Building with Amazon Bedrock and LangChain」を試してみました。
Building with Amazon Bedrock and LangChain
AWS社が公開しているワークショップです。本コラム執筆時点では英語版のみの提供です。そのため、ワークショップ中のプロンプトは基本的に英語で指定されています。
ワークショップは、us-west-2 (Oregon)リージョンか、us-east-1 (N. Virginia) リージョン利用が推奨されています。 日本語プロンプトを使ってみたい場合は、基盤モデルとしてAnthropic社のClaudeを利用します。
Claudeを使ってみる
ワークショップを進めていくと、モデル選択を行えるようになります。workshop/labs/langchainフォルダーの bedrock_langchain.py ファイルを編集します。

ここでは、Amazon Bedrockをインポートするよう指定します。
import os
from langchain.llms.bedrock import Bedrock
上記により、Bedrock クライアントが作成されます。クライアントを使用すると、標準の LangChain 呼び出しを実行し、自動でBedrock のモデルで動作するようになります。
ここでClaudeの指定を行います。
llm = Bedrock( #create a Bedrock llm client
credentials_profile_name=os.environ.get("BWB_PROFILE_NAME"), #sets the profile name to use for AWS credentials (if not the default)
region_name=os.environ.get("BWB_REGION_NAME"), #sets the region name (if not the default)
endpoint_url=os.environ.get("BWB_ENDPOINT_URL"), #sets the endpoint URL (if necessary)
model_id="ai21.j2-ultra-v1" #set the foundation model
)
デフォルトではmodel_idが「ai21.j2-ultra-v1」となっており、AI21 Labs社のJurassic-2が指定されています。
Claude2.0の場合は model_id を「anthropic.claude-v2」へ変更し、Claude2.1の場合は、model_idを「 anthropic.claude-v2.1」とします。
llm = Bedrock( #create a Bedrock llm client
credentials_profile_name=os.environ.get("BWB_PROFILE_NAME"), #sets the profile name to use for AWS credentials (if not the default)
region_name=os.environ.get("BWB_REGION_NAME"), #sets the region name (if not the default)
endpoint_url=os.environ.get("BWB_ENDPOINT_URL"), #sets the endpoint URL (if necessary)
model_id="anthropic.claude-v2.1" #set the foundation model
)
LangChains の予測関数を使用して呼び出しを行います。また、Bedrock クライアントは応答を自動的に文字列で返します。
response_text = llm.predict(prompt) #return a response to the prompt
ここまででClaude2.1をLangChainで使う準備ができました。
LangChain は、要件に応じて外部コンポーネントをプラグインできる拡張可能なライブラリです。
Amazon Bedrockで利用可能な Anthropic Claude モデルで動作ができる方法について解説しました。どのようにLLMアプリを構築していくかはまたの機会にお伝えできればと思います。

