
みなさん、こんばんは。小寺です。
Glueクローラーでパーティションインデックスが自動的に追加されるようになりました。
https://aws.amazon.com/about-aws/whats-new/2023/04/aws-glue-crawlers-creating-partition-indexes/
AWS Glue クローラーとは
AWS Glueの全体像を整理してみました。ワークフロー管理などもできます。
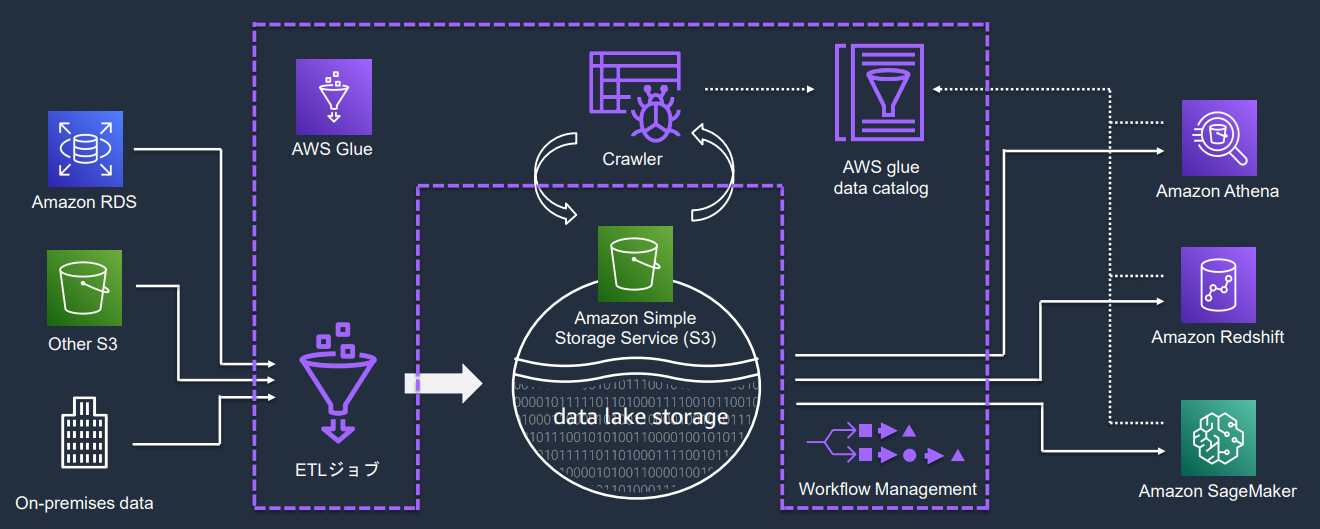
AWS Glueはサービス間でデータを簡単に移動できるようにするための、サーバーレスデータ統合サービスです。構成要素としては、大きくは以下に分かれます。
・Extract, Transform, and Load(ETL)ジョブ
・AWS Glue Studio
・AWS Glue Data Catalog
・Crawler(クローラー)
・AWS Glue DataBrew
・Workflow Management
・AWS Glue Elastic Views
ここでは細かい機能については、割愛しクローラーの役割について確認してみたいと思います。
クローラーは、Glueのデータカタログにメタデータを作成するプログラムで、優先度に従って、スキーマ情報を自動で判断し、スキーマを作成する機能があります。まず、クローラーがクロールできるデータストアについては、以下の通りです。
| クローラーが使用するアクセスタイプ | データストア |
|---|---|
| ネイティブクライアント | Amazon Simple Storage Service (Amazon S3)Amazon DynamoDBDelta Lake |
| JDBC | Amazon RedshiftSnowflakeAmazon Relational Database Service (Amazon RDS) 内、または Amazon RDS の外部:Amazon AuroraMariaDBMicrosoft SQL ServerMySQLOraclePostgreSQL |
| MongoDB クライアント | MongoDBMongoDB AtlasAmazon DocumentDB (MongoDB 互換性) |
現在、AWS Glue クローラーは、Amazon S3 および Delta Lake ターゲットのパーティション インデックスの作成をサポートしています。
今回のアップデート内容
AWS Glue クローラーで新しく検出されたテーブルのパーティション インデックスが自動的に追加されるようになりました。このクローラー機能のアップデートにより、Amazon AthenaやAWS Glueなどの分析サービスがパーティション処理を最適化し、高度にパーティション化されたテーブルでのクエリパフォーマンスがアップするようになりました。
特定のテーブル内のパーティションの数は、テーブル作成時から増加傾向にありますよね。 Amazon Athena のような分析サービスが何百万ものパーティションを含むテーブルをクエリすると、パーティションの取得に必要な時間が増加し、クエリの実行時間が長くなる傾向にあります。
本アップデートによりAWS Glue クローラーが新しい AWS Glue Data Catalog テーブルを作成するときに、手動で作成する必要はないです。なんと、デフォルトでパーティション インデックスも作成してくれます。
よって、パーティション インデックス キーから高速で検索可能なインデックスを作成し、数百万のパーティションを持つテーブルのパーティション メタデータの取得とフィルタリングに今までかかっていた時間が短縮できます。
注意事項
クローラーによって作成されたテーブルには、デフォルトでは変数 partition_filtering.enabled がないです。また、暗号化されたパーティションのパーティション インデックスの作成はサポートされていないです。
