
なさん、こんにちは。サニービュー事業部の小寺です。
もう約1か月ほど前ですが、re:Inventでセッション名「Data resiliency design patterns with AWS 」に参加したので内容について、レポートします。
資料はこちら。
そもそものデータレジリエンスって
データ・レジリエンスとは、サイバー攻撃、データの盗難、災害、障害、人為的ミスなどによるデータの破壊から保護し、迅速に回復する能力を意味します。
もともと、企業などの情報セキュリティ施策として、外部からの攻撃を未然に防止・抑止するための対策を取ってきてはいますが、攻撃パターンも進化していきます。外部もしくは内部からの攻撃によって受けるダメージをどうやって抑えていけばよいのか?
そのために、レジリエンスの考え方を取り入れ、攻撃が成功し被害を受ける前提で、早期にトラブルを検知できる仕組み作りや被害拡大を防止し、影響範囲や損害の深刻さを最小限に留める仕組み、迅速に元の状態に復旧できるような取り組みを意味しています。
セッションでは、IDCによるとクリティカルなアプリケーションのダウンタイムにかかるビジネスインパクトは、1時間あたり5000千万ドルから100万ドルにも及ぶとのことでした。
もちろんAWSにおいても同様なデータレジリエンスの考え方があります。

“Everything fails, all the time” – Werner Vogels (CTO, Amazon.com)
「全ては壊れる」ことを前提にしましょう
障害を未然に防止しようとするのでは無く、障害を自動で検知し、障害が自動で対処される仕組みを設計する
クラウドのデータを保護するために
オンプレミスのデータ保護のためのデータレジリエンスについても紹介がありましたが、本コラムでは
主にクラウドのデータレジリエンスを高める方法について、お伝えします。
まずはディザスタリカバリーの戦略についてです。セッション内ではコストと運用の複雑さ、保護と復旧時間のバランスによって、4つのアプローチに分かれています。
・Backup and Restore
・Pilot Light
・Warm Standby
・Multi-site Active/Active
・Backup and Restore
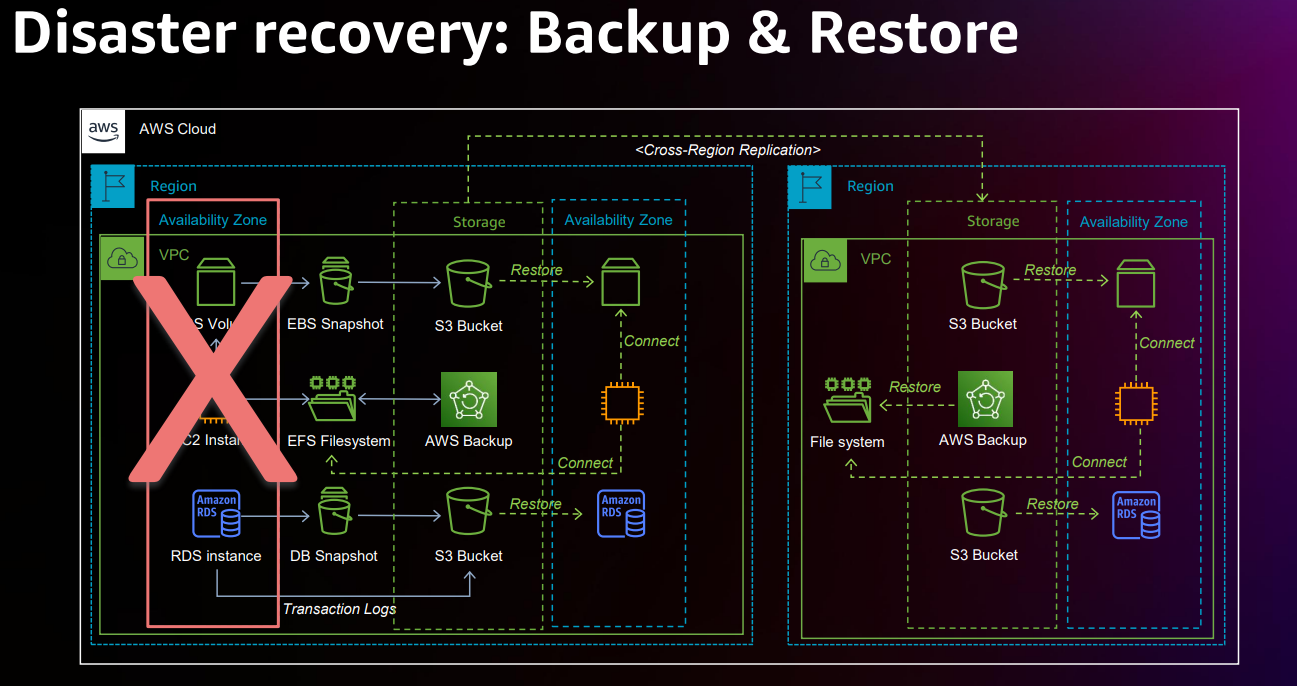
AZ でシンプルなアプリケーションをEC2で動かしている想定です。このインスタンスでは3種類のストレージが利用可能です。EBS ボリューム、EFS ファイルシステム、RDS インスタンスです。
ディザスタリカバリを目的にバックアップするた、EBS ボリュームは EBS スナップショットを取得します。
EFS ファイルシステムは AWS バックアップを使用してデータを保護します。
RDSインスタンスはデータベースのスナップショット取得します。
トランザクションログを S3 バケットにプッシュしていれば、個々のトランザクションまで復元することが可能です。
もし、別のリージョンへリストアする場合は、S3 バケットと EFS ファイルシステムをバックアップリージョンにレプリケートすればOKです。
リソースの展開と復元に時間がかかるかもしれませんが、費用対効果の高いデータ保護が可能です。
・Pilot Light
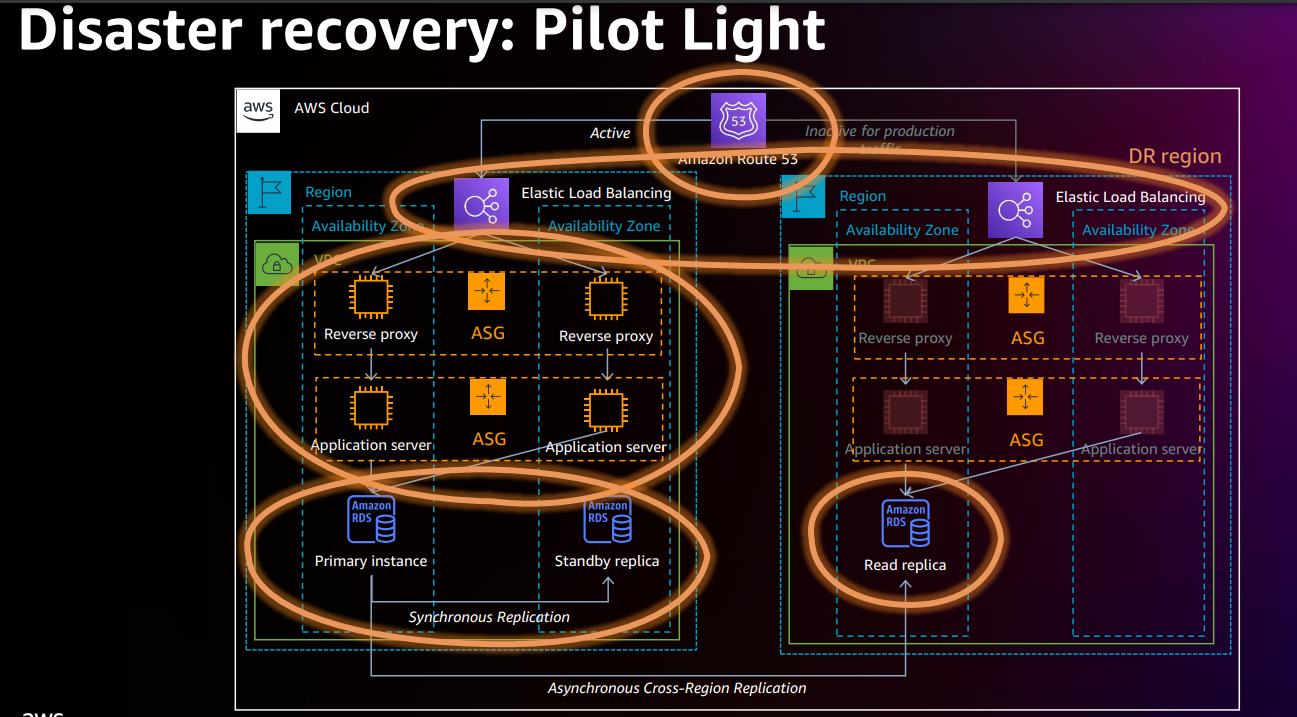
図の向かって、右側が DR リージョンで、データベースのリードレプリカは一番下にあります。 クロスリージョンレプリカを使用してプライマリデータを数秒でDRリージョンに複製しています。
DR リージョンでは、VPC、サブネット、ELB 、EC2 AutoScalingの設定までやっておき、インスタンスは起動しな状態にします。
DR リージョンは基本的にゼロインスタンスで構成されますが、DR リージョンをアクティブするときは?
DR リージョンのリード・レプリカをプライマリに昇格させます。 これで、書き込みができるようになります。EC2 AutoScaling の起動台数を増やしアプリケーションを実行するようにします。
そして最後に Route 53でDNSの向き先を更新し、クライアントからの通信を DR リージョンに送ります。
・Warm Standby
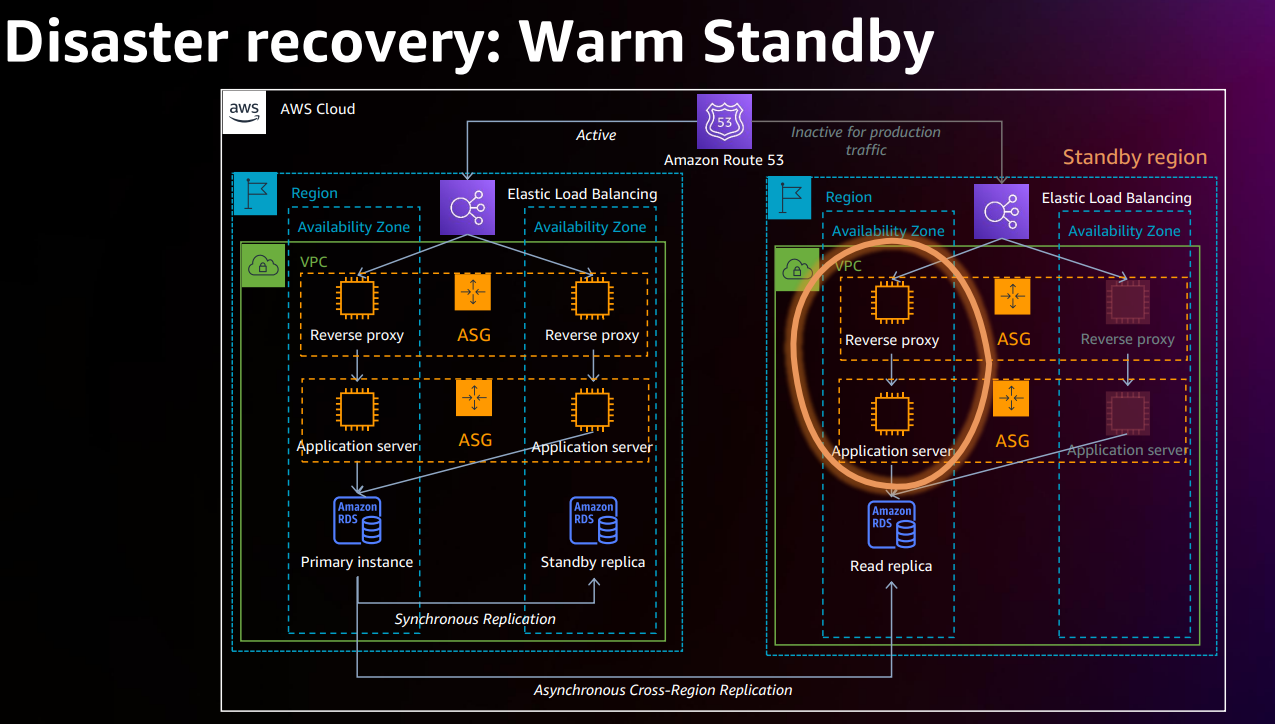
パイロットランプのデザインパターンとは似ていますが、パイロットスタンバイとの違いはアクティブなアプリケーションサーバーが DR リージョンにあることです。よって、フェイルオーバーをより迅速に行うことができます。
パフォーマンスの観点から、全負荷を処理するのに十分なインスタンスをスピンアップするために、オートスケーリンググループを調整する必要があります。
RTOがより高速になります。パイロットライトとウォームアップのどちらを選ぶかは?アプリケーション要件のRTO時間によって決まります。
・Multi-site Active/Active
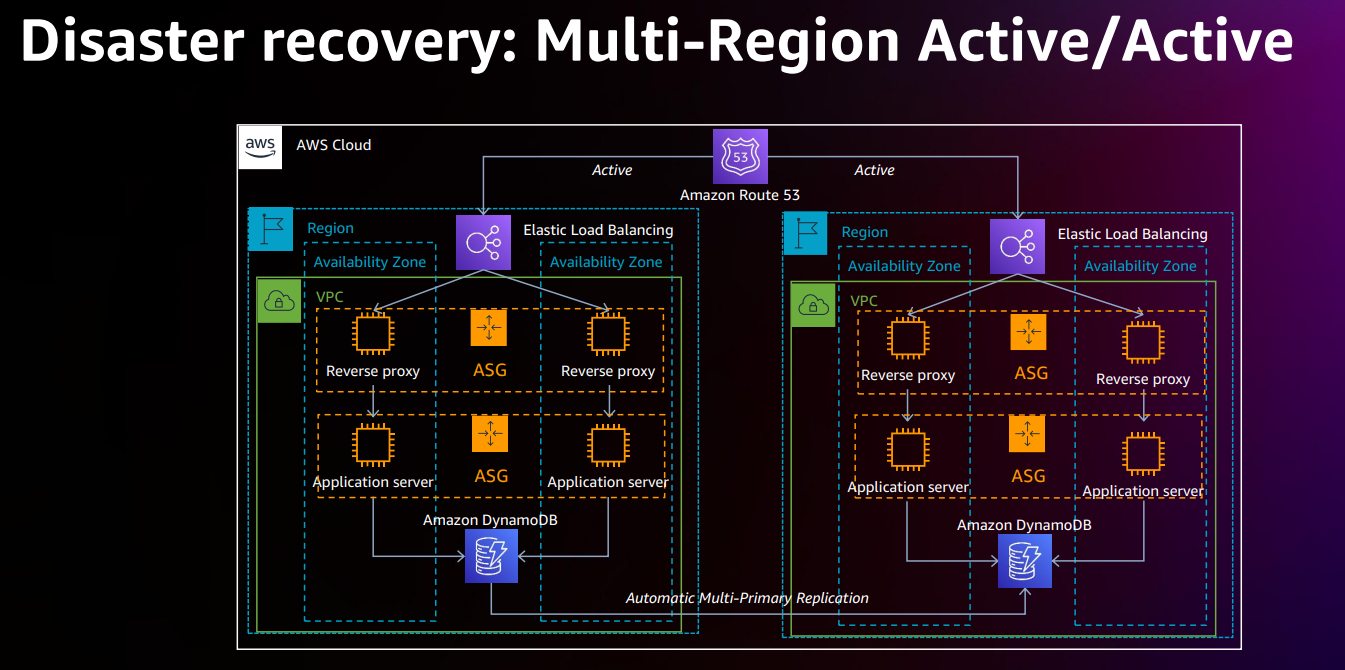
ダウンタイムやデータ損失がNGな要件がある場合は、マルチリージョン・アクティブ・アーキテクチャを採用することになります。構成図のトップにあるRoute 53は、2つのリージョンでアクティブになっています。クライアントを両方のリージョンにフルタイムで転送しています。両方のリージョンで Auto Scaling Group がずっと起動しています。
一番下にあるのは、DynamoDB の場合です。 データストレージを RDS から DynamoDB に変更しています。DynamoDB はリージョナルサービスです。 AZ レベルの停止やリージョン全体のイベントから保護されるためです。
アプリケーションは、ローカルに書き込んで競合書き込みに対処するか、グローバルに書き込んで高いレイテンシに対処するかを選択する必要があります。
このようなアクティブ・マルチリージョンの設計は、最高のデータ回復力がありますが、コストや設計の複雑性がそれなりにかかります。
レジリエンスって管理できるもの?
レジリエンスを管理、測定などすることができるのでしょうか?「壊れる前提」とはいいながらも何か保証を求めたくなりますよね。(あくまで私見です・・・)
そんなときに役立つのが、AWS Resilience Hubというサービスです。2021年11月にGAになっていますね。
AWS Resilience Hub は、AWS 上のアプリケーションの回復力を定義、検証、追跡するためのサービスです。アプリケーションごとに RTO と RPO の目標を定義することができます。
目標を決めた後は、アプリケーションの構成を評価して、要件を満たしていることを確認します。実用的なレコメンデーションと耐障害性スコアが出てきます。
また、時間の経過に伴うアプリケーションの耐障害性の変化をモニタリングできます。Resilience Hub は、 AWS マネジメントコンソールからアクセスでき、評価の実行、事前構築済みテストの実行、アラームの設定を行って問題を特定し、アラートを送ることもできます。
このセッションで学んだ構成に変更した後など、評価をしたいっていうときに活用できるサービスですね。
まとめ
オンプレミスも含めたデザインパターンを多く知ることができたセッションでした。また、セッション内で紹介はされたもののこの記事には書ききれなかったDRS(AWS Elastic Disaster Recovery)についても、別途お伝えしたいと思います。
