
みなさん、こんにちは。サニービュー事業部の小寺です。
re:Invent 2022の発表の中でもSunny Cloudで良く使っているサービスGlue。
GlueのSDPも発表されましたね。なかなか触れる機会がなかったのですが、Glue4.0についてご紹介します!
AWS Glueとは
今まで、Glueそのものについて、お伝えしたことがなかったので、この機会にGlueの歴史も振り返ってみたいと思います。
AWS Glue は、データ統合と ETL処理の開発と実行を行うための、スケーラブルな大量のデータ処理向けのサーバーレスデータ統合サービスです。
ここで、ETL処理って何?と思った方のために簡単に解説すると、ETLツールは、データの抽出(Extract)・データの変換(Transform)・データの書き出し(Load)を行う処理です。
データを抽出・変換・加工しDWH(データウェアハウス)へ渡す処理を主には行います。ビジネス・インテリジェンス(BI)用にDWHを構築する際には必須のプロセスとして知られています。ETL処理を行うためのツールもAWS Glue以外に世の中には存在します。
・データの抽出(Extract)
自社システムや他お客様向けサービス等のデータベースからデータの抽出を行います。どのような利用目的でデータを抽出するのかを明確にする必要があります。
利用目的を明確にすることで、不要なデータは抽出されず、その後のデータ変換、データ書き出しの作業をスムーズに進めることができます。抽出の目的というよりは、どのようなデータを何に使って、何を分析したいのか?がまずは重要です。
・データの変換(Transform)
DWHに書き出しやすいように、一定の規則に従いデータの変換・加工を行い、データを正規化します。
「抽出」のプロセスでDWHに書き出しやすい統一されたデータ形式になっていれば、このプロセスは省略することもできます・
・データの書き出し(Load)
ひとつ前の変換・加工のプロセスで作成したデータファイルをDWHへ書き出します。ここでは、DWH側のインポート機能を利用することで
スピードアップした取り込みができる場合もあります。もちろん利用するETLツールにもよります。
AWS Glueの機能
この世の中にたくさんあるETL処理ツールではありますが、AWS Glueは最近ではデータ統合ツールとして単なるサーバレスなETL処理ツールではありません。
そんなAWS Glueの機能と特徴についてお伝えします。
・ETLジョブ
ETL作業を実行するため、データソースから必要なデータを抽出します。
Glueには「Apache Spark」と「Python Shell」という2つのジョブタイプがあり、以下の2つのタイプでデータ変換ジョブを実行します。
「Apache Spark」タイプは、「Apache Spark」のクラスタを制御して大規模分散処理を実行します。ジョブを起動すると、「ドライバー」と複数の「エグゼキューター」が起動し、スクリプトは「ドライバー」で実行されます。
「Python Shell」タイプは、Pythonスクリプトを実行するためのジョブです。
・クローラ
データレイクをクローリング(定期的にチェック)し、データカタログへメタデータを登録・更新します。
ここでいうメタデータとは、どのようなデータが入っているかという情報です。
・データカタログ
永続的なメタデータストアです。データそのものではなく、あくまでETL処理を行う際に必要なテーブル定義、ジョブ定義やその他制御情報を保持しています。
またデータカタログは、AWSアカウント毎に一つ用意されていて、データカタログをもとに必要なデータをロードし分析等を実行します。
・ワークフロー
ETLジョブ、クローラ、データカタログ出力までの一連の処理を自動化するための機能です。ETLジョブによるデータ取り込みからクローラーの起動によるデータカタログへの登録は、従来はLambdaなどを使ってきましたが、Lambda連携は視認性が悪く、自動化にも手間がかかっていました。Glueのワークフロー機能を利用することで、Glueのサービスとして可視化が可能で、自動化も行えるようになりました。
・Glue StudioとGlue DataBrew
AWS Glueでも、2020年9月に「Glue Studio」、2020年11月に「Glue DataBrew」がリリースされています。
・Glue Studio
AWS Glue Studioは、AWS GlueでETLジョブを簡単に作成、実行、監視できる新しいグラフィカルインターフェイスです。
ボックス(ノード)と矢印(流れ)のシンプルなインターフェイスを用いて、データの移動や変換、AWS Glueで実行するジョブを作成できます。プルダウンメニューやチェックボックスなどを選択するだけでサーバーレスなApache SparkベースのETL処理を構築することが可能で、Apache Sparkプログラミングに不慣れなユーザーでも簡単にGUIで処理ができるようになっています。
・Glue DataBrew
AWS Glue DataBrewとは、データのクリーニングと正規化をサポートするデータ準備ツールです。
データクレンジングをビジュアルに行えるツールです。AWS社によれば、従来よりも80%速く作業ができるとのことです。また、 「AWS Glue DataBrew」 で適用したすべての変換処理を、レシピから一覧表示で確認することができます。レシピジョブを実行することにより、出力は S3 に保存されます。
AWS Glueの歴史を振り返る
改めてAWS Glueの歴史をドキュメントの履歴を辿り、振り返ってみました。
初めてのGlueのリリースはなんと、2017年8月14日です。歴史あるサービスですね。
- 2017年8月14日 AWS Glueリリース
- 2017年11月 XML形式のデータソースと新しいクローラー構成オプションがサポート
- 2018年4月 ジョブ実行時のタイムアウトしきい値の設定がサポート
- 2018年5月 クローラーの新しい構成オプション マージNewColumnsがサポート
- 2018年7月 データソースとしてDynamoDBをサポート
- 2018年7月 Apache Spark job metricsをサポート
- 2019年5月 クローラー ソースとしての既存の Data Catalog テーブルのサポート
- 2019年6月 VPCエンドポイントをサポート
- 2020年8月 待望のGlue2.0。Apache Spark ETL ジョブ実行時の起動時間が短縮されました!
- 2020年12月 Glue2.0でストリーミング ETL ジョブの実行のサポート
- 2021年5月 ブループリントからのワークフロー作成(この時点でpublic preview)
- 2021年8月 Glue 3.0発表ー。Apache Spark ETL ジョブを実行するための Apache Spark 3.0 エンジンのアップグレード、およびその他の最適化とアップグレードなどなど。
- 2021年11月 Lake Formationの管理テーブルをサポート
- 2022年4月 Auto ScallingがGAに
- 2022年10月 AWS Glueの「AmazonS3イベント通知を使用した加速クロール」をサポート
- 現在にいたる・・。この他にも数えきれないくらいのアップデートがありました。
AWS Glue4.0に飛び込もう
ってGlue4.0発表コラムのリンクにあったので、その通り飛び込んでみましょう。
・エンジンのアップデート
Apache Spark 3.3.0 、 Python 3.10、Scala 2.12 に対応しました。
・ Pandas API に対応
Apache Spark 3.3.0に対応したことにより、PythonライブラリであるPandasが利用できるようになりました。
・新しいデータ形式に対応
Apache Hudi、Apache Iceberg、Delta Lakeのデータフォーマットがサポートされるようになりました。
•コネクタのアップグレードに対応
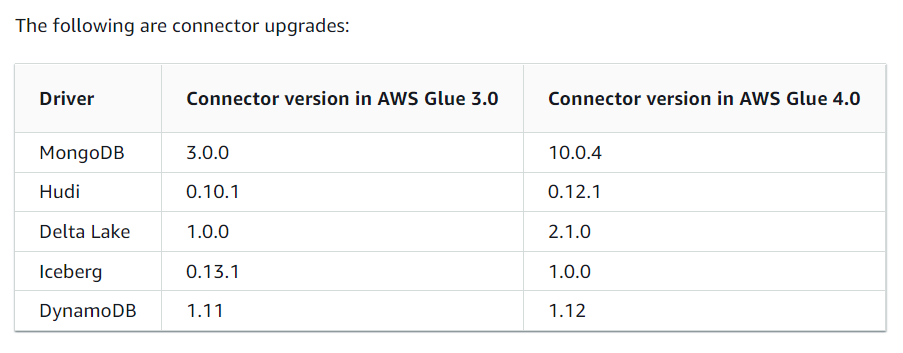
•Cloud Shuffle Storage Pluginのサポート
Spark 用の S3ベースのCloud Shuffle Storage Plugin がネイティブサポートされ、処理実行時にディスク使用量をスケール可能になりました。
•実行中にクエリを動的に最適化する Adaptive Query Execution も利用可能に
AWS Glue 4.0の制約事項
re:Inventでの発表時点での制約事項は以下の2つです。
・AWS Glue ストリーミング ジョブと AWS Glue インタラクティブ セッションは、AWS Glue 4.0 ではまだ利用できません。
・AWS Glue 機械学習と個人識別情報 (PII) 変換は、AWS Glue 4.0 ではまだ利用できません。
まとめ
いかがでしたでしょうか。Glueとは何か?Glue4.0の特徴について、理解の一助となれば幸いです。
