
みなさん、こんにちは。サニービュー事業部の小寺です。
re:Inventで新サービス「Amazon Athena for Apache Spark」が発表されました。
https://aws.amazon.com/jp/about-aws/whats-new/2022/11/amazon-athena-now-supports-apache-spark/
Amazon Athena for Apache Sparkとは
Amazon Athena は、あらゆるサイズのデータに対する高速分析ワークロード向けに最適化された、人気のあるオープンソースの分散処理システムである Apache Spark をサポートするようになりました。
Athena は、データ レイク、データベース、その他のデータ ストアなど、ペタバイト規模のデータが存在する場所を問わずクエリを実行できるインタラクティブなクエリ サービスです。
Amazon Athena for Apache Spark を使用すると、SQL に加えて、Athena の合理化されたインタラクティブなサーバーレス エクスペリエンスを Spark で利用できます。
Athena コンソールまたは Athena API でより簡単に利用できるようになったApache Spark ワークロードを実行し、Jupyter Notebook をインターフェイスとして使用して Athena でデータ処理を実行し、Athena API を使用してプログラムで Spark アプリケーションと対話できます。
Athena を使用すると、インタラクティブな Spark アプリケーションが 1 秒未満で起動し、最適化された Spark ランタイムでより高速に実行されるため、結果を待つのではなく、より多くの時間をインサイトに費やすことができます。
Athena がインフラストラクチャの管理と Spark 設定の構成を担当するため、ユーザーはアプリケーションの開発により集中できますね。
実際に起動してみるには
(1)Athenaからまずワークグループを作成し、「ワークグループを作成する」を選びます。
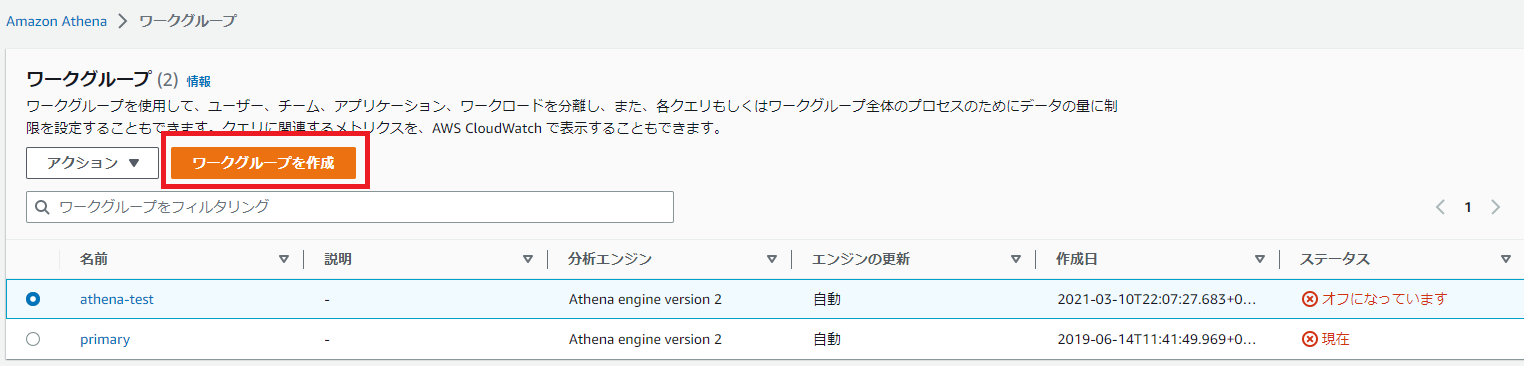
(2)ワークグループの名前を入力します。
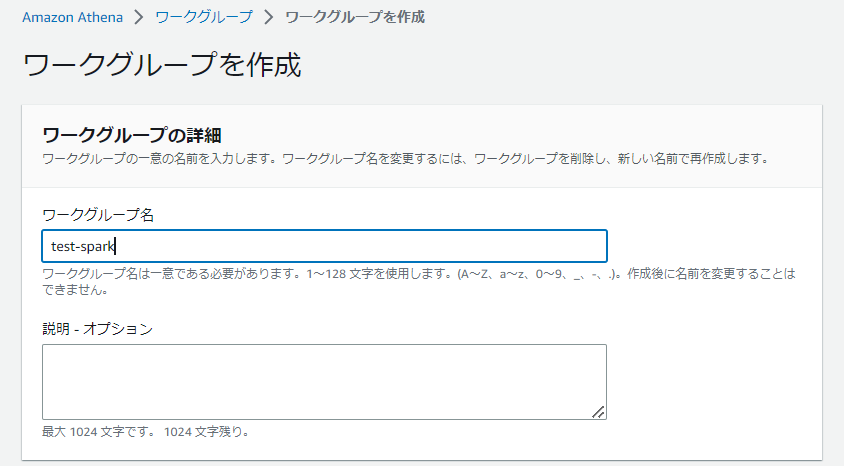
(3)同じページでApache SparkをAhenaのエンジンとして選びます。
また、「サンプルノートブックをオンにする」にチェックします。

(4)計算結果の設定では「新しいS3バケットを作成」を選びます。
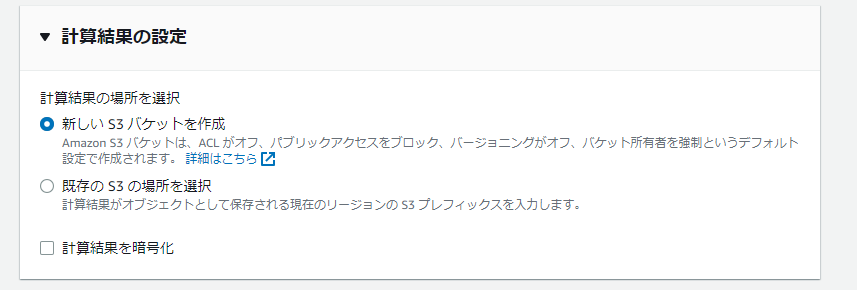
(5)ワークグループを作成します。
(6)新しいワークグループができたことを確認します。
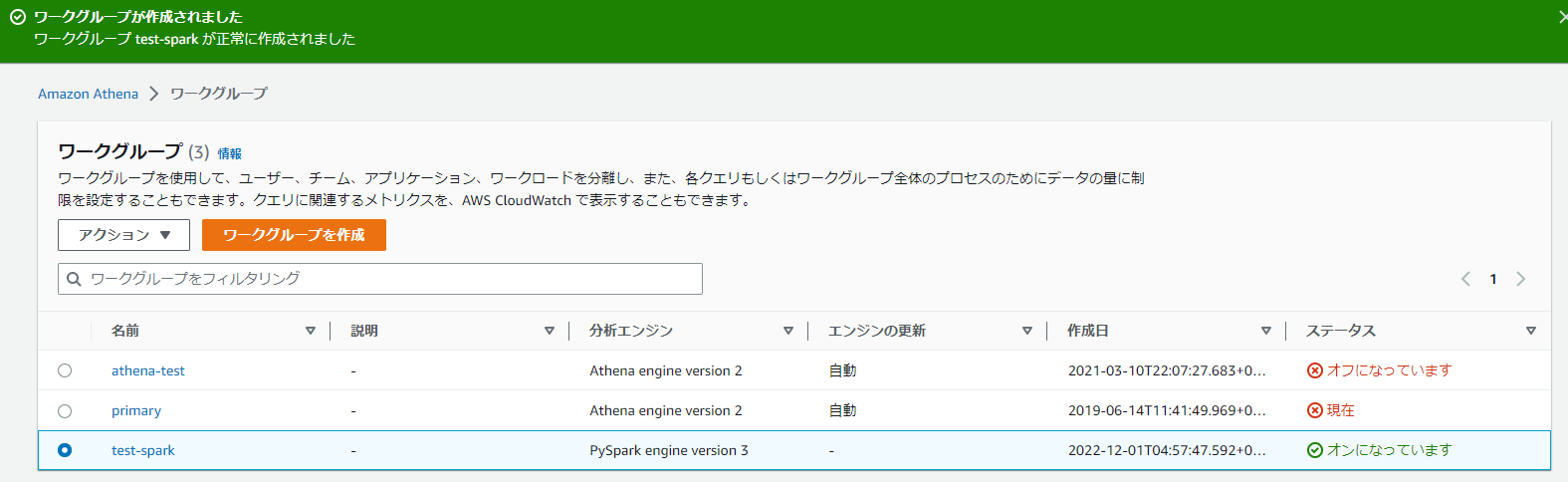
(7)ワークグループの詳細を確認するために、「計算結果の場所」のリンクをクリックします。
また既に作成されているノートブックに新しくファイルをインポートして、新しくノートブックを作成することもできます。
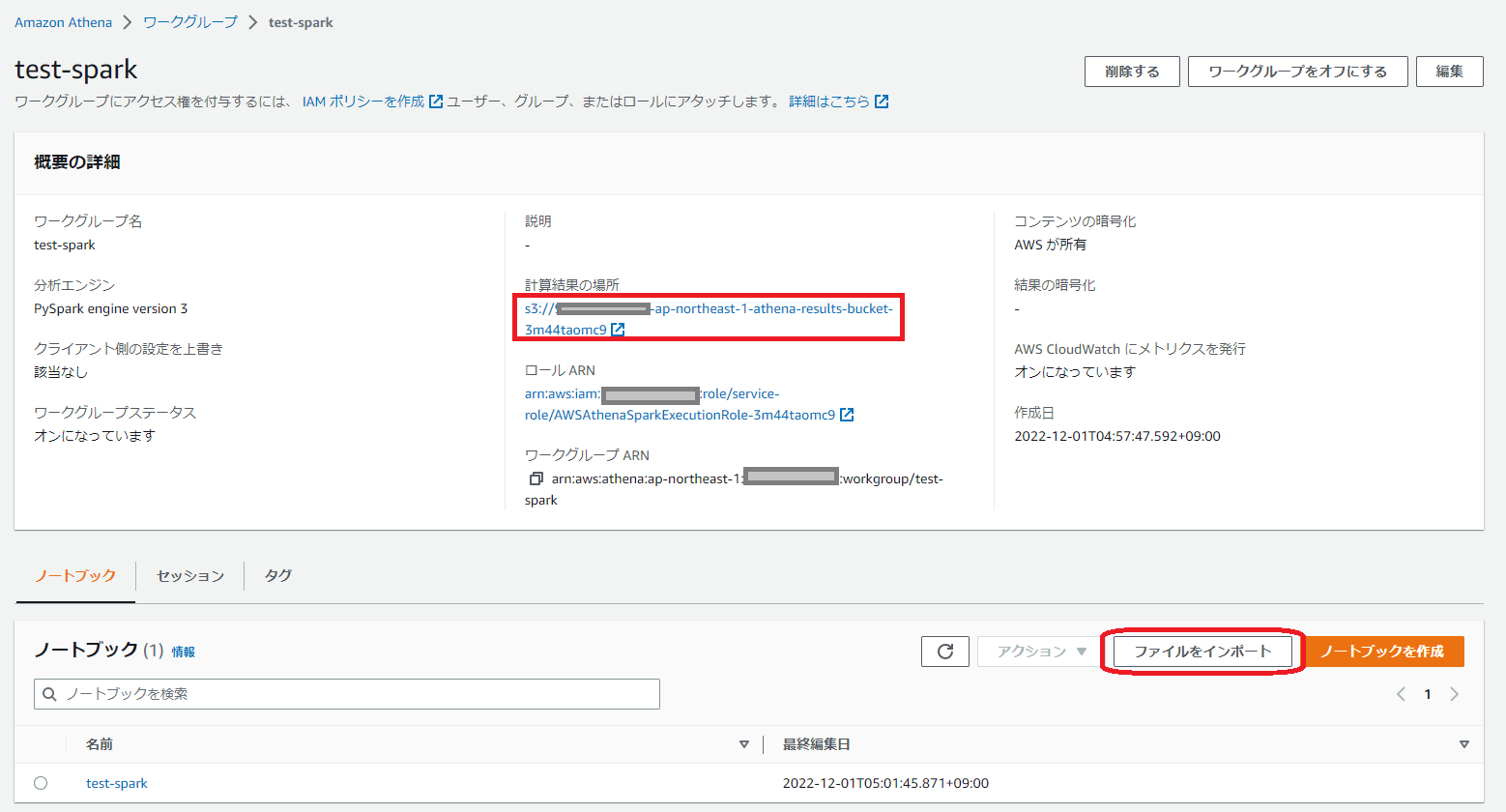
(8)例えば、 Jupyter notebook を選んだ場合は、以下の通りアプリケーションが開始できます。

対応リージョン
以下の5つのリージョンで利用可能です。東京リージョンでも利用できます。
・US East (Ohio)
・US East (N. Virginia)
・US West (Oregon)
・Asia Pacific (Tokyo)
・Europe (Ireland)
